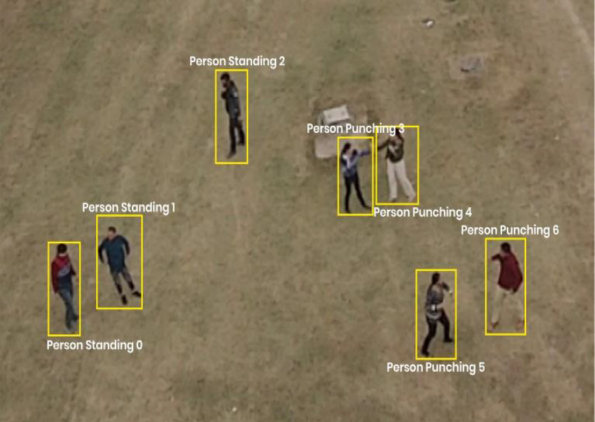
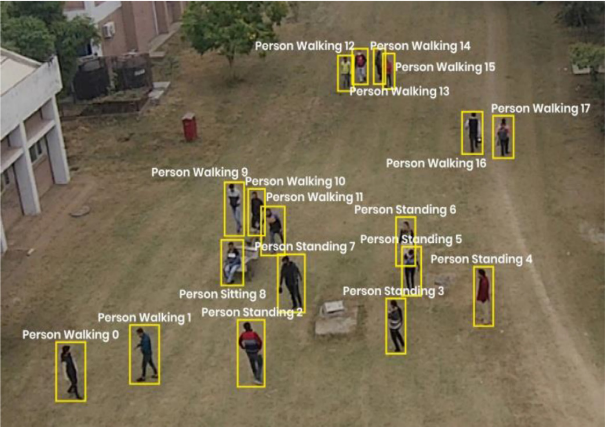
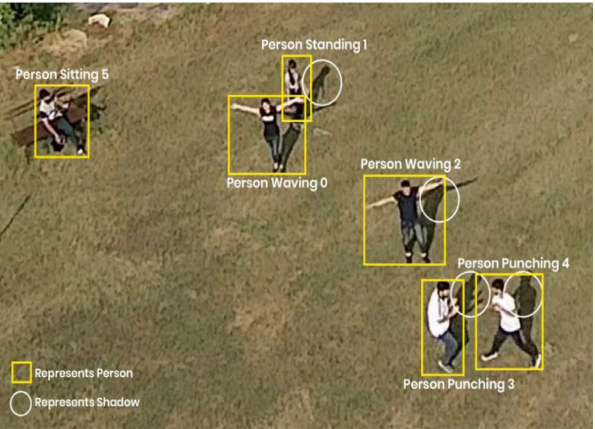
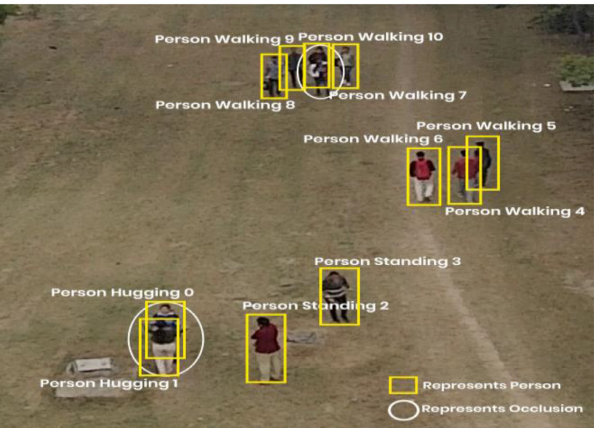
Aeriform in-action is a multiview dataset for recognizing human
actions in aerial videos. The proposed dataset consists of 32 high
resolution videos containing 13 action classes with 55,477 frames
(without augmentation) and 400,000 annotations captured at
30fps and a resolution of 3840 x 2160 pixels. The dataset addresses
several concerns like camera motion, illumination changes, diversity
in actions, dynamic transitions of actions etc. The action classes can
be categorized as atomic actions, human- human interactions and
human-object interactions. The 13 actions are carrying, drinking,
handshaking, hugging, kicking, lying, punching, reading, running,
sitting, standing, walking and waving. This dataset will provide a
baseline for recognizing human actions in aerial videos and will
encourage the embedding researchers to progress the field.